Machine & Mechanical Design
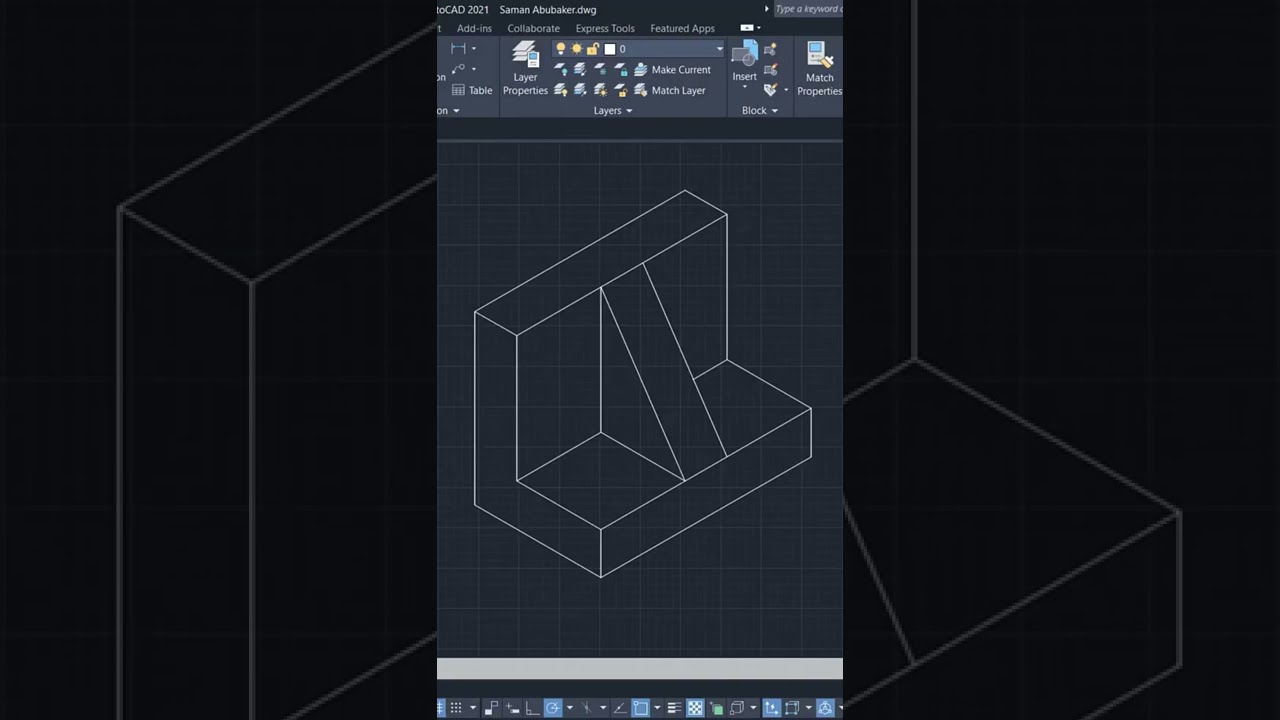
Technical Overview: AutoCAD Isometric Drawing Exercise 2s
This article provides an in-depth technical analysis of 'AutoCAD Isometric Drawing Exercise 2s', covering key mechanism structures, engineering operational principles, and essential parameters for technical understanding.
In-Depth Structural & System Analysis
AutoCAD Training Exercise for Beginners Video Tutorial on How to Create Isometric Drawing in AutoCAD for Beginners Technical ...
Key Takeaways & System Summary
Through careful analysis of 'AutoCAD Isometric Drawing Exercise 2s', understanding internal mechanisms and driving systems significantly optimizes operational efficiency and maintenance standards.




